
SQL
Structuced Query Language:结构化查询语言,通过此语言让程序员和数据库软件进行交流
DBMS
DataBaseManagementSystem:数据库管理系统(数据库软件)
- 常见的集中DBMS:
- MySQL:Oracle公司产品,08年被Sun公司收购,09年Sun公司被Oracle收购。开源产品,MariaDB实际上就是MySQL的一个分支,使用方式和MySQL一样,市占率排名第一
- Oracle:Oracle公司产品,闭源产品,性能最强,价格最贵,市占率排名第二
- SQLServer:微软公司产品,闭源产品,市占率第三
- DB2:IBM公司产品
- SQLite:轻量级数据库,安装包几十K,只具备最基础的增删改查功能
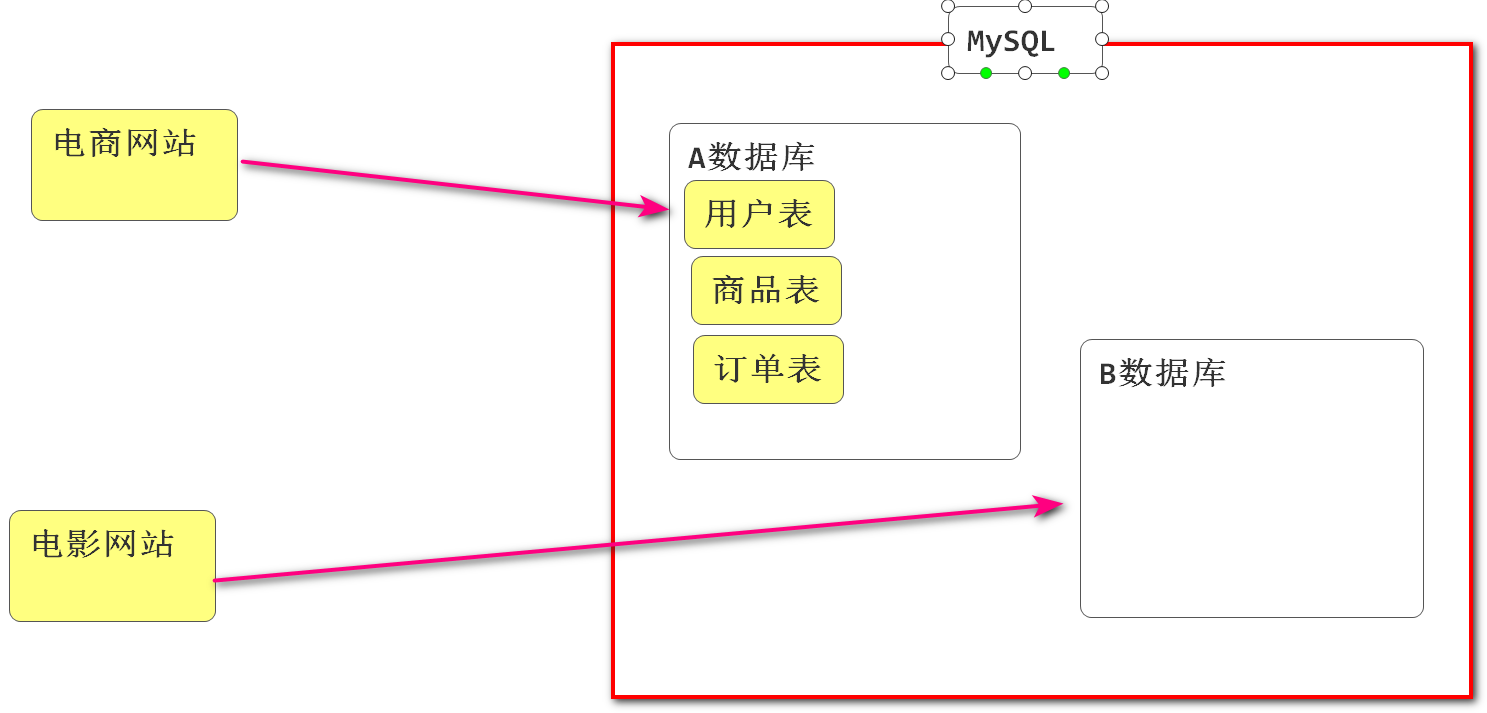
数据库和表的概念
- 在MySQL数据库软件中保存数据,需要先建库,然后在库里面建表,然后把数据保存到表中!
SQL语句格式
- 以 ; 结尾
- 关键字不区分大小写
- 可以有空格或换行,但一定要以 ; 结尾
数据库相关的SQL语句
查询所有数据库:show databases;
创建数据库:create database 数据库名 charset=utf8/gbk;
查看数据库信息:show create database 数据库名;
删除数据库:drop database 数据库名;
使用数据库:use 数据库名;
执行表相关和数据相关的SQL语句之前必须使用了某个数据库
表相关的SQL语句
- 创建表:create table 表名(字段名1 类型,字段名2 类型,......);
- 查询所有表:show tables;
- 查询表信息:show create table 表名;
- 查询表字段:desc 表名;
- 修改表名:rename table 原名 to 新名;
- 删除表:drop table 表名;
- 添加表字段
- 最后面添加:alter table 表名 add 字段名 类型;
- 最前面添加:alter table 表名 add 字段名 类型 first;
- 在xxx字段后面添加:alter table 表名 add 字段名 类型 after xxx;
- 删除表字段:alter table 表名 drop 字段名;
- 修改表字段:alter table 表名 change 原名 新名 新类型;
数据相关的SQL语句
操作数据必须保证已经使用了某个数据库并且已经准备好了保存数据的表
- 插入数据
- 全表插入:insert into 表名 values(值1,值2);
- 指定字段插入:insert into 表名(字段名1,字段名2) values(值1,值2);
- 查询数据:select 字段信息 from 表名 where 条件;
- 修改数据:update 表名 set 字段名=值 where 条件;
- 删除数据:delete from 表名 where 条件;
主键约束+自增
- 主键:表示数据唯一性的字段称为主键
- 约束:创建表时给表字段添加的限制条件
- 主键约束:限制主键的值(唯一且非空)
- 格式:create table t1(主键名 主键类型 primary key,值1 类型1.....)
- 自增规则:从历史最大值基础上+1
- 格式:create table t1(主键名 主键类型 primary key auto_increment,值1 类型1.....)
SQL语句分类
- DDL:数据定义语言,包括数据库相关和表相关的SQL语言
- DML:数据操作语言,包括增删改查
- DQL:数据查询语言,只包含select查询相关的SQL语言
- TCL:事务控制语言
- DCL:数据控制语言
数据类型
- 整数:int(m)和bigint(m);m代表显示长度
- 浮点数:double(m,d);m代表显示长度,d代表小数长度
- 字符串:
- char(m);固定长度,执行效率略高,当保存数据的长度相对固定时使用,最大值255
- varchar(m);可变长度,更节省空间,最大值65535,但推荐保存短的数据(255以内)
- text(m);可变长度,最大值65535,建议保存长度大于255的
- 日期:
- date,只能保存年月日
- time,只能保存时分秒
- datetime,保存年月日时分秒,默认值null,最大值 9999-12-31
- timestamp(时间戳,距离1970年1月1日的毫秒数),保存年月日时分秒,默认值为当前系统时间,最大值 2038-1-19
去重distinct
- select distinct 字段 from 表名;
is null和is not null
查询有领导的员工姓名
select name from emp where manager is not null;查询没有领导的员工姓名
select name from emp where manager is null;
and 和 or
查询1号部门工资高于2000的员工信息
select * from emp where dept_id=1 and sal>2000;查询1号部门或者工资等于3000的员工信息
select * from emp where dept_id=1 or sal=3000;
比较运算符 > < >= <= = != 和 <>
- 查询工作不是程序员的员工信息
- select * from emp where job!="程序员";
- select * from emp where job<>"程序员";
between x and y 两者之间
- 查询工资在2000到3000之间的员工信息
- select * from emp where sal>=2000 and sal<=3000;
- select * from emp where sal between 2000 and 3000;
in 关键字
- 查询工资等于5000,4000,3000的员工信息
- select * from emp where sal=5000 or sal=4000 or sal=3000;
- select * from emp where sal in(5000,4000,3000);
模糊查询like
%:代表0或多个未知字符
_:代表1个未知字符
举例:
查询名字姓孙的员工信息
select * from emp where name like "孙%";查询名字以精结尾的员工姓名
select * from emp where name like "%精";查询工作第二个字是售的员工信息
select * from emp where job like "_售%";查询名字中包含僧的员工信息
select * from emp where name like "%僧%";
排序 order by
格式:order by 字段名 asc(升序,默认)/desc(降序)
举例:
查询所有员工信息并按照工资升序排序
select * from emp order by sal; select * from emp order by sal asc;查询所有员工信息并按照工资降序排序
select * from emp order by sal desc;
分页查询
格式:limit 跳过的条数,请求的条数(每页的条数)
跳过的条数=(请求的页数-1)*请求的条数
举例:
查询第1页的5条数据
limit 0,5
查询第6页的8条数据
limit 40,8
别名
- select name as "姓名" from emp;
- select name "姓名" from emp;
- select name 姓名 from emp;
聚合函数
通过聚合函数可以对查询的多条数据进行统计查询
平均值:avg(字段名)
查询1号部门的平均工资
select avg(sal) from emp where dept_id=1;
最大值:max(字段名)
查询1号部门的最高工资
select max(sal) from emp where dept_id=1;
最小值:min(字段名)
查询1号部门的最低工资
select min(sal) from emp where dept_id=1;
求和:sum(字段名)
查询1号部门所有员工的工资总和
select sum(sal) from emp where dept_id=1;
计数:count(*)
查询程序员的数量
select count(*) from emp where job="程序员";
数值计算 + - * / %
查询每个员工的姓名,工资和年终奖(年终奖=5个月的工资)
select name,sal,sal*5 年终奖 from emp;给1号部门的员工每人涨薪5元
update emp set sal=sal+5 where dept_id=1;
分组查询 group by
格式:group by 分组的字段名
举例:
查询每个部门的平均工资
select dept_id,avg(sal) from emp group by dept_id;查询每种工作的最高工资
select job,max(sal) from emp group by job;
having
where后面只能写普通字段的条件,不能包含聚合函数
having后面可以包含聚合函数的条件,需要和group by 结合使用,写在group by的后面
举例
查询平均工资高于2000的部门
select dept_id,avg(sal) from emp group by dept_id having avg(sal)>2000;查询每个部门的工资总和,只查询有领导的员工,并且要求工资总和大于5400
select dept_id,sum(sal) s from emp where manager is not null group by dept_id having s>5400;
各个关键字的书写顺序
- select 查询的字段信息 from 表名 where 普通字段条件 group by 分组字段名 having 聚合函数条件 order by 排序字段名 limit 跳过条数,请求条数;
子查询(嵌套查询)
查询工资大于2号部门平均工资的员工信息
select * from emp where sal>(select avg(sal) from emp where dept_id=2);查询工资高于程序员最高工资的员工信息
select * from emp where sal>(select max(sal) from emp where job="程序员");查询拿最低工资员工的同事们的信息
select * from emp where dept_id=(select dept_id from emp where sal=(select min(sal) from emp)) and sal != (select min(sal) from emp);
关联关系
指创建的表和表之间存在的业务关系
有以下几种关系:
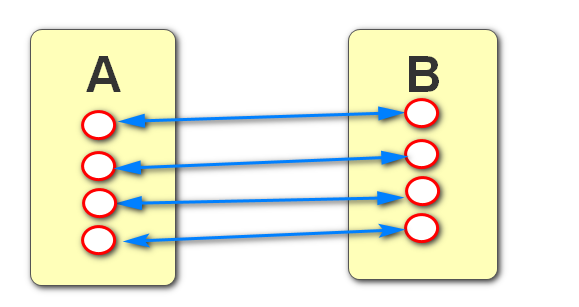
一对一:有AB两张表,A表中的一条数据对应B表中的一条数据,同时B表中的一条数据也对应A表中的一条数据
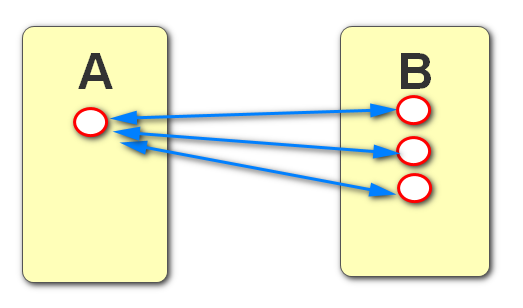
一对多:有AB两张表,A表中的一条数据对应B表中的多条数据,同时B表中的一条数据对应A表中的一条数据
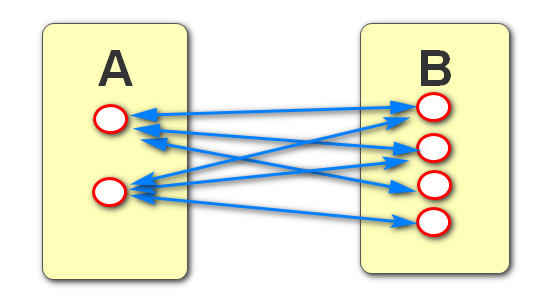
多对多:有AB两张表,A表中的一条数据对应B表中的多条数据,同时B表中的一条数据也对应A表中的多条数据
表和表之间通过外键字段建立关系
- 一对一:在任意表中添加一个建立关系的字段指向另一张表的主键
- 一对多:在多的表中添加建立关系的字段(外键)指向另一张表的主键
- 多对多:需要创建一个单独的关系表,里面至少包含两个字段分别指向另外两个表的主键
关联查询
同时查询多张表数据的查询方式称为关联查询
关联查询包括:
等值链接
格式:select * from A,B where 关联关系
举例:查询工资高于2000的员工姓名和对应的部门名
select e.name,d.name,sal from emp e,dipt d where e.dept_id=d.id and sal>2000;
内连接
格式:select * from A join B on 关联关系
举例:查询工资高于2000的员工姓名和对应的部门名
select e.name,d.name,sal from emp e join dept d on e.dept_id=d.id where sal>2000;
外连接
等值链接和内连接查询到的都是两张表的交集数据
外连接查询的是一张表的全部和另外一张表的交集数据
格式:select * from A left/right join B on 关联关系
举例:
查询所有员工姓名和对应的部门名
select e.name,d.name from emp e left join dept d on e.dept_id=d.id;查询所有部门的名称,地点和对应的员工姓名和工资
select d.name,loc,e.name,sal from emp e right join dept d on e.dept_id=d.id;
等值链接和内连接查询的是两张表的交集数据,推荐使用内连接
如果需要查询一张表的全部和另外一张表的交集时,使用外连接,只需要掌握左外即可,因为表的位置可以交换
JDBC
JavaDataBaseConnectivity:Java数据库链接
通过Java语言和MySQL数据库进行链接并执行SQL语句
JDBC是Sun公司提供的一套专门用于Java语言和数据库进行了解的API(Application Programma Interface应用程序编程接口)
Sun公司为了避免Java程序员,每一种数据库软件都学习一套全新的方法,通过JDBC接口将方法名定义好,让各个数据库厂商根据此接口中的方法名写各自的实现类(就是一个jar文件,称为数据库的驱动),这样Java程序员只需要掌握JDBC接口中方法的调用,即可访问任何数据库软件
如何通过JDBC连接数据库并执行SQL语句
创建Maven工程
在工程的pom.xml文件中,添加MySQL驱动的依赖坐标
创建java文件,添加一下代码
//1.创建链接对象(异常抛出) Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/数据库名?charaterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false","用户名","密码"); //2.创建执行SQL语句的对象 Statement s = conn.createStatement(); //3.执行SQL语句,execute执行 s.execute("create table jdbct1(age int)"); //4.关闭资源 conn.close();
执行SQL语句的对象Statement
- execute("sql");测方法可以执行任意SQL语句,但建议执行DDL(数据库相关和表相关的SQL语句)
- int row = executeUpdate("sql");此方法用来执行增删改相关的SQL语句,返回值表示生效的行数
- ResultSet re = executeQuery("sql");此方法用来执行查询相关的SQL语句,返回值ResultSet叫做结果集对象,查询到的数据都装在此对象中
DBCP 数据库连接池
DataBaseConnectionPool
作用:将连接重用,从而提高执行效率
如何使用数据库连接池
//创建连接池对象DruidDataSource ds = new DruidDataSource(); //设置数据库连接信息 url 用户名 密码 ds.setUrl("jdbc:mysql://localhost:3306/empdb?characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false"); ds.setUsername("root");ds.setPassword("root"); //设置初始连接数量 ds.setInitialSize(3); //设置最大连接数量 ds.setMaxActive(5); //从连接池中获取连接 异常抛出 Connection conn = ds.getConnection();
PreparedStatement预编译的SQL执行对象
- 此对象可以将编译SQL语句的时间点提前,提前候可以将SQL语句逻辑部分提前锁死,用户输入的内容将不能影响原有SQL语句的逻辑部分,从而解决了SQL注入的问题
- 如果SQL语句中存在变量,则必须使用PreparedStatement,解决SQL注入问题,而且可提高开发效率(避免了拼接字符串)
- 如果SQL语句中没有变量,可以使用Statement或PreparedStatement
数据库常见错误
| 异常名称 | 解释 | 解决方法 |
|---|---|---|
| Access denied for user 'root'@'localhost' (using password:YES) | 用户名或密码错误 | 检查用户名或密码 |
| Column count doesn't match value count at ... | 值的数量和字段名数量不匹配 | 检查表的字段是否正确,检查插入的值是否正确 |
| Duplicate entry '1' for key 'PRIMARY' | 主键值重复 | |
| Column 'id' cannot be null | 值不能为null | |
| Communications link failure | JDBC连接数据库错误 | 启动MySQL服务 |
| SSLException | SSL异常 | 在连接数据库的url添加useSSL=false |
| SQLSyntaxErrorException | SQL语句错误 | |
| Parameter index out of range | 参数位置超出范围 |