
数据库进阶
锁
锁的分类
- 按照锁的粒度分:表锁、行锁
- 按照锁的类型分:
- 共享锁
- 也叫做share锁、s锁
- 特点:可以给表加,也可以给行数据加,给目标数据加上share锁后允许其他事务继续对该数据加share说,不允许其他事务对该数据加排它锁;通常读取数据时使用;
- 排它锁
- 也叫做x锁
- 特点:给数据加排它锁,不允许其他事务继续给该数据加排它锁,同时也不允许其他事务同时给该数据加共享锁,适用于写操作。
- 共享锁
在数据库中,经常执行的读写操作为:
- select...
- insert...
- delete...
- update...
增删改操作默认给操作的行数据加排它锁,select操作默认不加任何锁
- 如何在查询是加共享锁、排它锁?
- 查询加共享锁:select...lock in share mode;
- 查询加排它锁:select...for update;
悲观锁和乐观锁
是两种思想
悲观锁
当多事务、多线程并发执行时,事务总是悲观的认为,在自己访问数据期间,其他事务一定会并发执行,此时会产生线程安全问题,所以为了保证线程安全,这个事务在访问数据时,会立即给数据加锁,从而保证线程安全。
synchronized、排它锁都是悲观锁的应用
乐观锁
在多事务、多线程并发执行时,某个事务总是乐观的认为,在自己执行期间,没有其他事务与之并发,认为不会产生线程安全问题,所以不会给数据佳作;但是确实存在其他事务与之并发执行的情况,确实存在线程安全问题,为了保证线程安全,通过版本号机制或CAS来保证线程安全。
事务
事务是数据库中执行操作的作息那执行单位,不可再分,要么全部成功,要么全部失败。
事务的四大特性
- 原子性
- 一致性
- 隔离性
- 持久性
数据库中事务自动提交默认开启
- 查看语句:show variables like 'autocommit'
- 如何关系事务自动提交:
- set autocommit = off;
- 事务管理:
- 开启事务:begin
- 提交事务:commit
- 回滚事务:rollback
死锁
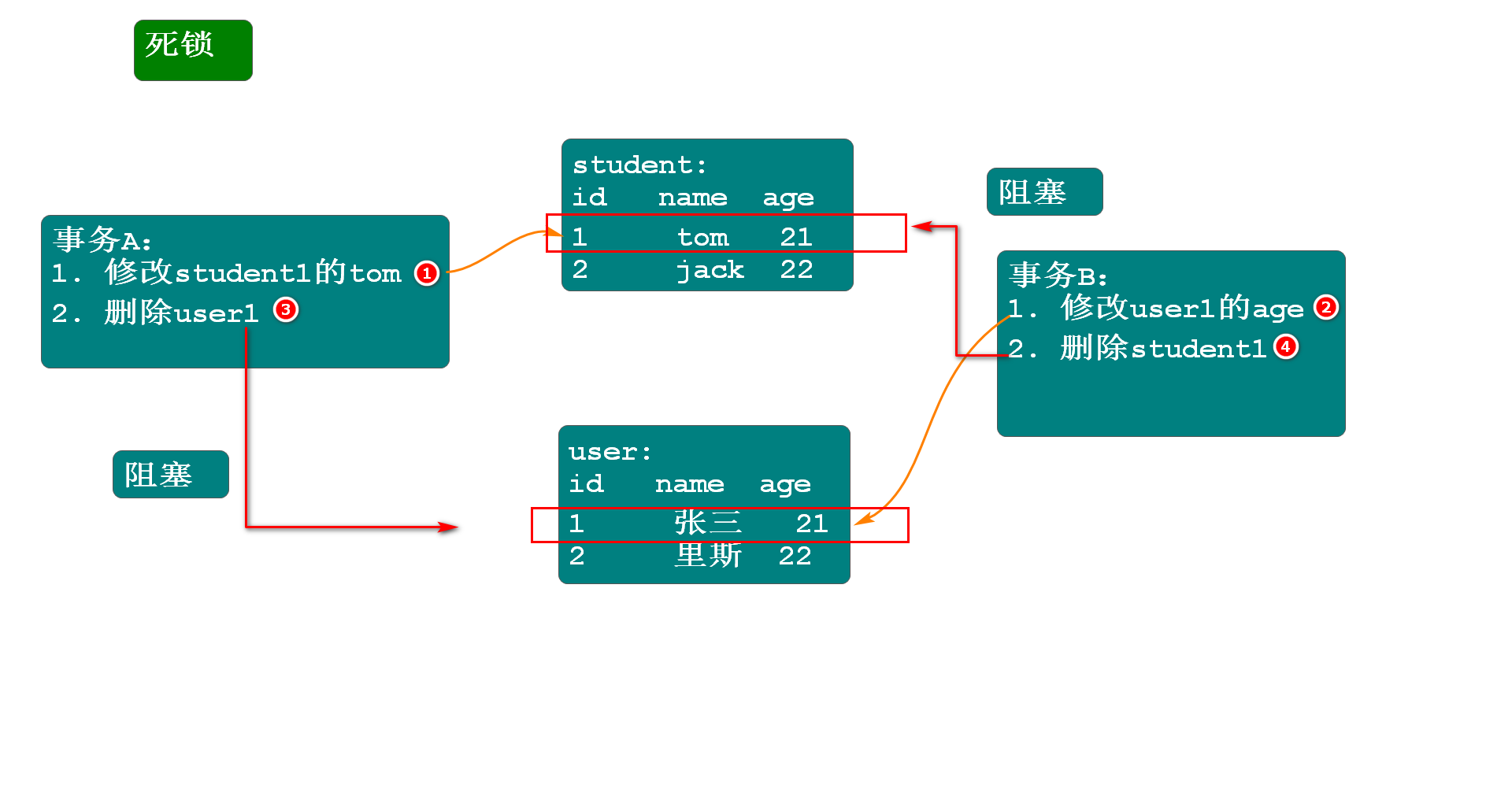
数据库中出现死锁,数据库是如何解决的?
clientA:
1. setautocommit=off
2. begin;
3. update student set sname=xx where sno=1
4. delete from course where cno=1
clientB:
1. setautocommit=off
2. begin;
3. update course set..where cno=1
4. delete from student where sno=1
mariadb对死锁的处理:检测到死锁后,让一端的事务回滚,并提示DeadLock,让另一端的事务执行成功.
事务隔离级别
读未提交
- read uncommitted
- 特点:事务一刻读取到其他事务未提交、未回滚钱的数据,会产生脏读
- 什么是脏读:由于事务读取到了其他事务未提交、未回滚前的数据,导致读取的数据最终是不存在的,这个现象就叫做脏读。

读已提交
- read committed
- 特点:事务只能读取到其他属兔提交、回滚后的数据,解决了脏读问题,但是会产生不可重复读问题
- 什么是不可重复读:在事务A执行期间,其他事务对事务A访问的数据进行修改操作,导致事务A中前后两次读取相同的数据的结构不一致,这个现象就叫做不可重复读

可重复度
- repeatable read
- 解决了不可重复读问题,产生了新的问题 -- 幻读
- 什么是幻读:在事务A访问数据期间,其他事务执行了插入操作,导致事务A前后两次读取到的数据总量不一致,这个现象就叫做幻读

可串行化
- serializable
- 解决了幻读问题,实现了多事务并发执行同步效果,所以这个隔离级别的并发效率时最低下的

四种隔离级别由低到高
读未提交-->读已提交-->可重复读-->可串行化
数据库默认的隔离级别
oracle和sql server 默认的隔离级别为 读已提交 mysql的 默认隔离级别为 -- 可重复读
MVCC(Multi-Version Concurrency Control)- 多版本并发控制
MVCC解决了并发安全问题,且并发执行效率高很多
- MVCC的实现有三部分配合实现:
- undolog
- mysql中的表里边每个表都有隐藏的三个字段
- ReadView
隐藏字段
- row_id -- Innodb存储引擎提供的隐藏主键 -- 当表中没有主键时自动生成
- DB_trx_id -- 事务的id -- 该列中保存的id值为最后操作该数据的事务id
- DB_rool_ptr -- 数据回滚指针,保存要回滚到的数据的地址
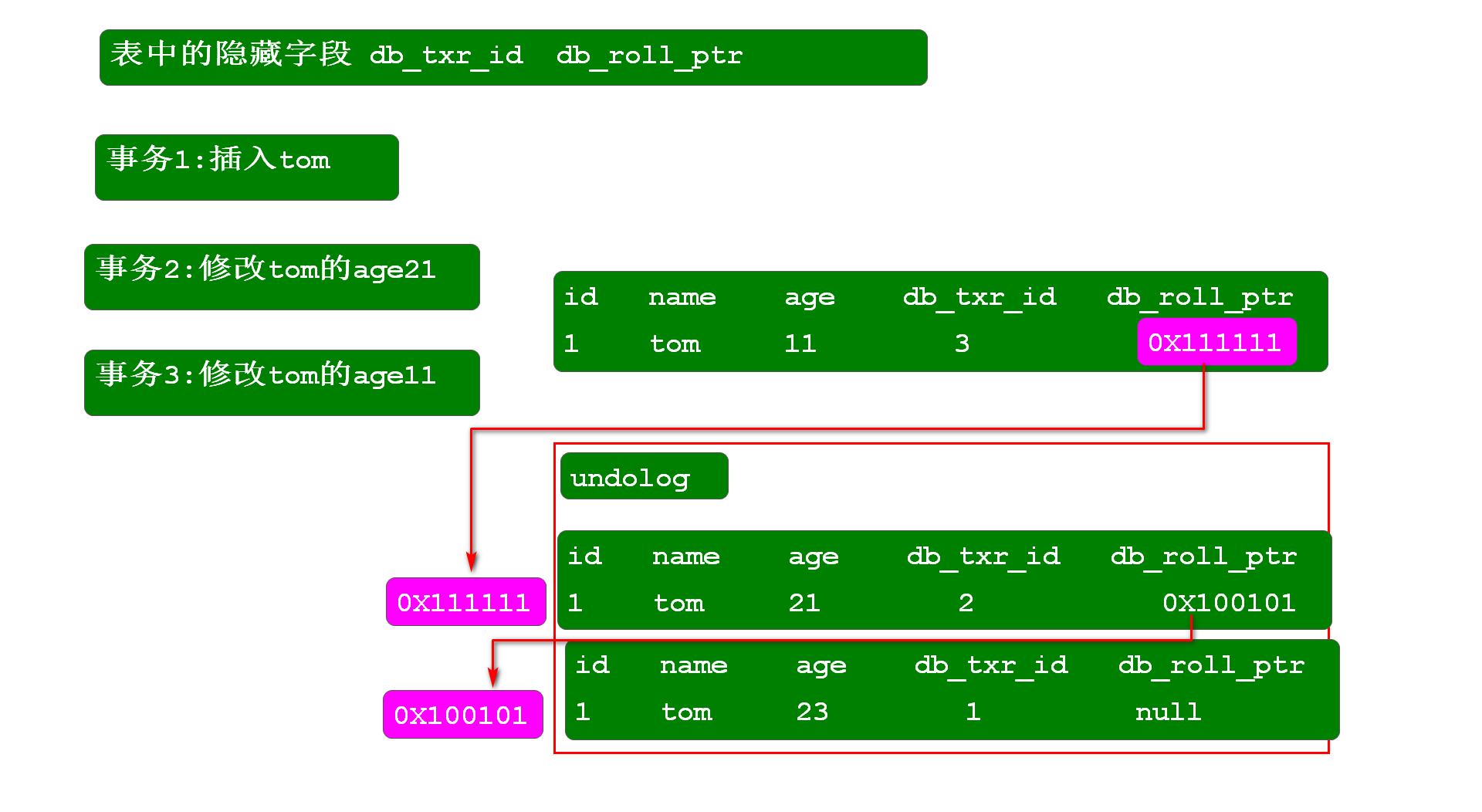
ReadView
事务执行操作时,会生成当前事务的ReadView,ReadView保存当前事务之前活跃的所有事务id
ReadView有四个字段:
- m_ids: 截止到当前事务id之前,所有活跃的事务id
- min_trx_id: 记录以上活跃事务id中的最小值
- max_trx_id: 保存当前事务结束后应分配的下一个id值
- creator_trx_id: 保存创建ReadView的当前事务id
三者如何配合实现mysql的隔离级别

索引
索引时作用于列上,用于对该列的值进行排序,形成一个目录,从而提高该字段的查询效率,索引适用于数据量大的表中
- 索引底层是B+Tree
- B+Tree是基于BTree
BTree的特点:
- 以数据块来保存元素,实现排序
- 每个数据块中最多保存degree-1个元素,当数据块中的元素数量达到度的值时,此时会进行分裂提取,将最中间的元素提取到上一级数据块中,将原数据块分裂成左右两个数据块
- 查询优势:每次比较会排除大量数据,无需读取这些数据,整体而言,树的高度是几,则读取几次数据块,查询次数会大大降低,查询效率会提高。
B+Tree和BTree的区别
- 叶子数据块之间用单向链表进行连接,为了提高区域范围内的数据查询效率
- 在叶子数据块分裂提取时,提取出去的元素依然存在于原叶子数据块中;但是若从非叶子数据块进行分裂提取,此时提取的数据不会再存在于原数据块中,保证最终查询的数据一定位于叶子数据块中,非叶子数据块存在的意义是作为目录存在
查询效率高:整体查询的次数降低了,不会对所有元素都查询,而是每次比较之后,可以排除大量数据
- 索引的高度固定为3,则度会根据数据量进行适当的调整
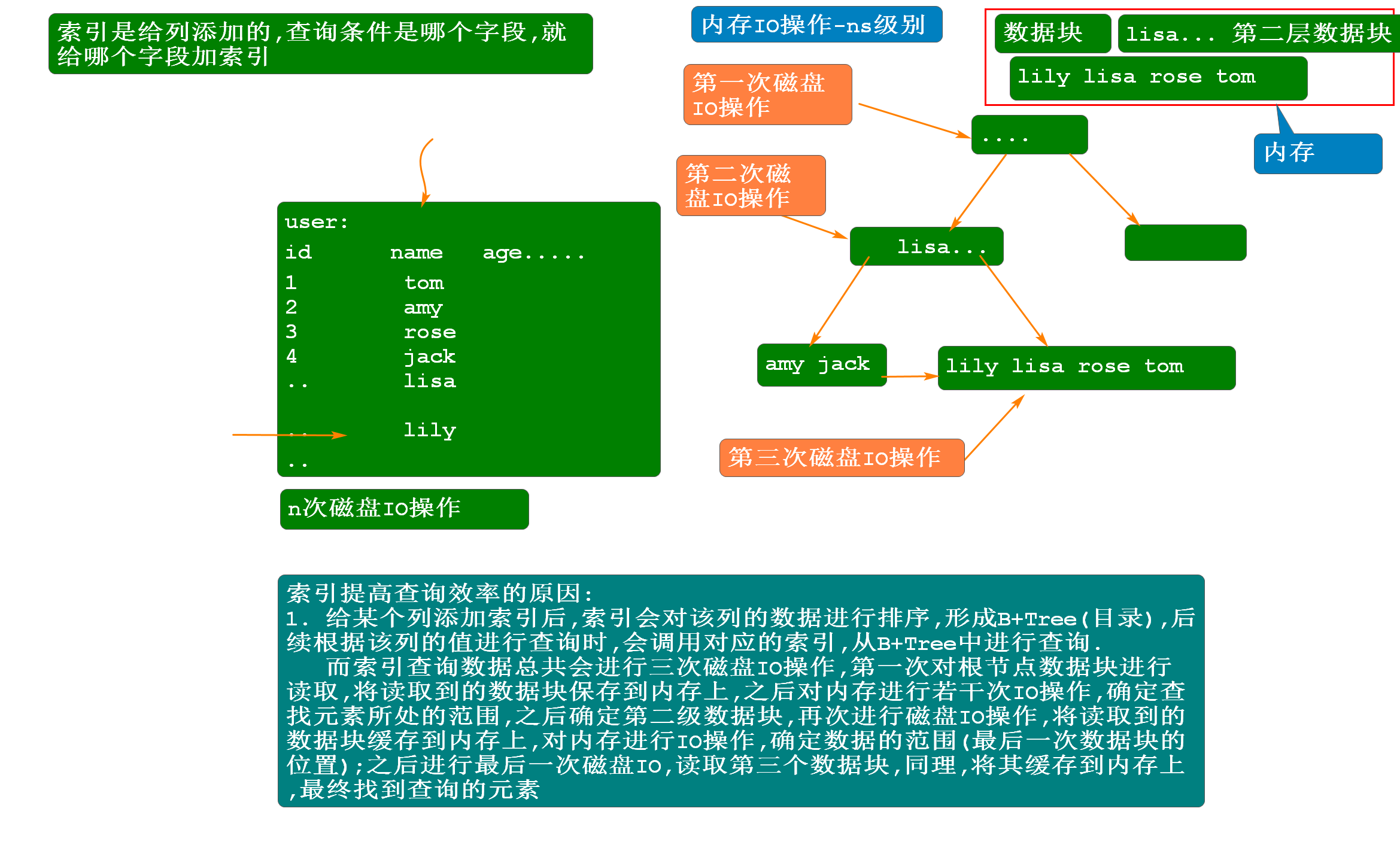
- 注意:将读取到的数据块缓存到内存上后,对内存中缓存的数据块中的数据进行读写,采用的是二分查找算法
- 索引的底层是B+Tree,但是索引对B+Tree进行了一些优化
- 索引使用B+Tree,在叶子数据块中保存的元素不是一个元素值,而是key—value
索引的分类
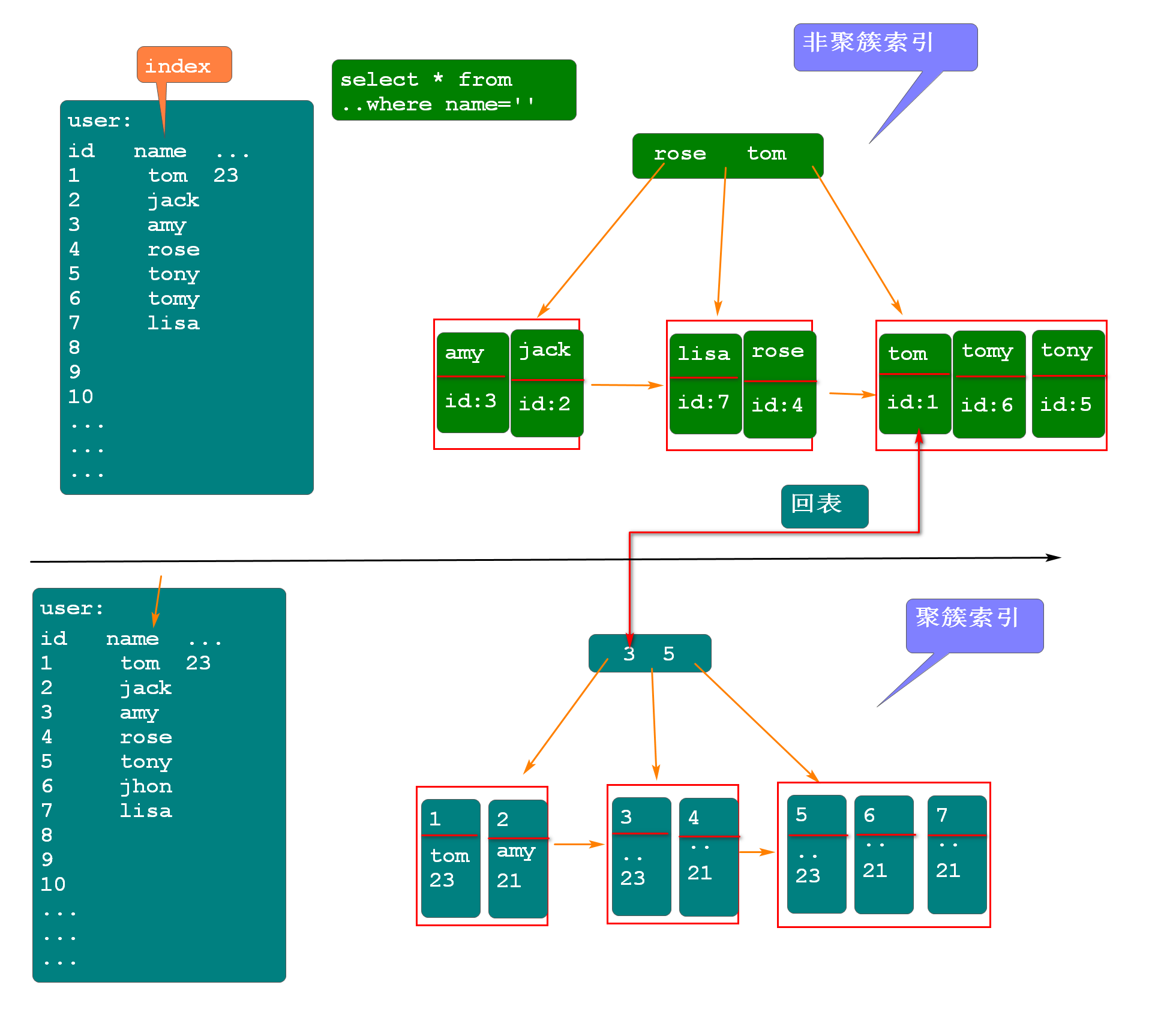
- 聚簇索引(聚集索引):给主键id添加的索引就叫做聚簇索引
- 非聚簇索引(非聚集索引):给非主键字段添加的索引叫做非聚簇索引
Innodb的特点
从mysql5.5开始存储引擎换为Innodb,该存储引擎有以下的特点:
- Innodb支持事务和行锁
- 默认会给表的主键添加聚簇索引;若表中没有提供主键,此时Innodb会自动给表添加隐藏主键,类型为long,长度为6,Innodb会给该主键添加聚簇索引
- 除聚簇索引外,Innodb默认还会给添加了unique约束以及外键的字段添加索引
聚簇索引
聚簇索引时Innodb存储引擎默认添加的,无需我们添加
聚蔟索引中的key和value分别保存什么?
- key:主键-id
- value:主键对应的行数据
聚簇索引中,根据id就可以直接找到对应的行数据
非聚簇索引
是需要我们手动添加的,其key和value分别是:
- key:保存添加了索引的那列的值
- value:这行数据对应的id(主键)
非聚簇索引中,根据添加了索引的那列的值,可以快速的找到对应的id,此时再根据id到聚蔟索引中,可以快速查询到对应的行数据,这个操作叫做回表操作
索引操作
- 创建索引
- create index index_name on table_name(col) 案例:给字段添加unique约束,验证是否Innodb默认给添加了索引 添加unique约束:
- alter table table_name add col type unique;
- create table table_name(id int primary key,name varchar(20) unique)
- create index index_name on table_name(col) 案例:给字段添加unique约束,验证是否Innodb默认给添加了索引 添加unique约束:
- 查询索引
- show index from table_name
- 删除索引
- drop index index_name on table_name
- drop index index_name on table_name
索引的适用场景
- 表中的数据量大是,应该使用索引,表中数据量不大,不要使用索引,因为建立索引也是需要时间的
- 通常会给作为查询条件的字段添加索引
- 当某字段的值被频繁修改时,不要给该字段添加索引,因为每次修改索引都会改变元素的排序,从而导致索引重构,耗费时间
- 在一个表中,索引并不是越多越好,通常情况下,一个表中的索引不要超过6个
索引失效场景
索引失效是指:因为一些不当操作,导致进行全表扫描,而不使用索引,这种情况我们叫做索引失效
使用索引时sql语句要避免的情况:
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描 where name is not null /is null
- 应尽量避免在 where 子句中使用!=操作符,否则将引擎放弃使用索引而进行全表扫描
- 应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描 where name=xx or age=xx or col=xx 若其中一个字段没有索引,其他有索引的字段也不会走索引
- not in 也要慎用,否则会导致全表扫描,in并不会导致索引失效 where ..not in(xx,xx,xx) 适用in 会不会适用索引? -- 会
- 尽量避免在where子句中对字段使用like左侧模糊查询(like '_%'),会导致全表扫描 where xx like '%xx' /like '_x'
- 应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描 eg: select...from user where age+4>12
- 应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描 eg:select...from ...where round(score)=.... {.grid-list}
索引并不是越多越好,索引固然可以提高响应的select的效率,但同时也降低了insert和update的效率,因为insert或update时有可能会重建索引,所以怎样建左印需要慎重,视具体情况而定,一个表的索引最好不要超过六个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。 {.is-warning}
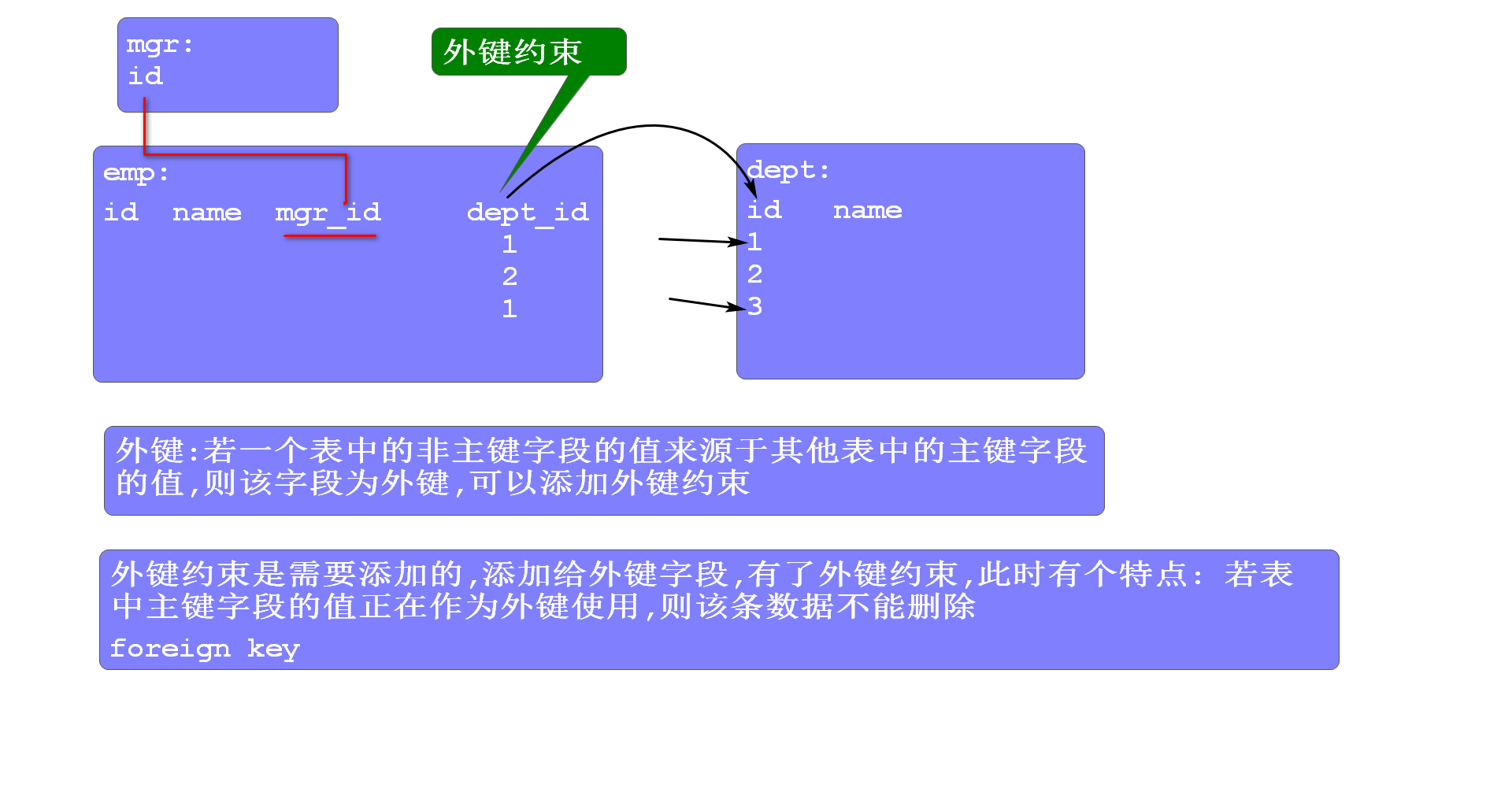
数据库的五大约束
- 主键约束 -- 要求数据非空且唯一
- 唯一性约束 -- unique,要求数据唯一
- 外键约束 -- foreign key,特点:若主键的值正在作为外键被使用,则不能删除该条数据
- 非空约束 -- not null,要求数据不能为空
- 检查约束 -- check(age between 18 and 20),要求插入的数据中的age必须在18-20之间
视图
什么是视图
视图是虚拟表,用于展示结果集,其中并不保存数据,其数据来源于真实表中,视图实质上是用于封装sql的,后续若想再次执行相同的sql,直接调用视图名称即可。
- 场景:
- 在数据库中若要多次展示同样的数据,其数据来源于4表,一样的sql写多次,此时出现了sql重复问题 数据库如何解决这个问题? 将上述的sql封装起来,给这个sql起一个名字,后续若想再次执行该sql,直接调用名字即可 create view view_name as select...from A join B ....
视图操作
- 创建视图
- create view view_name as select...
- create view view_name(col1,col2,col3,col4) as select...
- 调用视图:因为视图是虚拟表,所以对视图的操作和对表的操作是一样的
- select ... from view_name
- desc view_name
- 删除视图
- drop view view_name
视图注意事项:
- 视图实质上是对sql的封装,而不是对结果集的封装,视图的存在并不适用于提高查询效率,效率不会提高
- 视图的存在适用于查询,而不是对数据进行写操作,所以不应该对视图执行update操作,但是数据库语法上允许对视图执行update操作,但是不一定成功
- 视图来源于单表
- 修改 -- 成功
- 删除 -- 成功
- 增加 -- 成功
- 视图来源于多表
- 修改
- 修改一张表的字段 -- 成功
- 同时修改2表的字段 -- 失败
- 删除 -- 失败
- 增加 -- 失败
- 修改
- 视图来源于单表
- 因为视图中并不保存数据,起数据来源于真实表中,所以正式表中的数据发生改变,视图中的数据一定会随之改变
如何进行慢sql优化
- 进行sql优化的第一步,是先查找哪些查询sql执行效率低。
慢sql日志功能:
- 在mysql中会有一个日志文件用于记录执行时间超过指定时间的sql,这个日志文件就叫做慢sql日志。
- 该功能在mysql中默认不开启,若想使用该功能,需要开启
- 操作慢sql日志的sql语句:
- 查看男sql日志是否打开:show variables like 'slow_query_log';
- 开启慢sql日志功能:set golbal show_query_log=1;
- 查询男sql日志设置的时间:show global variables like 'long_query_time';
- 如果需要,可以修改设置时间(阈值时间):set golbal long_query_time=2;
- 查看日志文件:show variables like 'slow_query_log_file';
注意点:对慢sql日志功能设置完成,需要重启数据库服务器,才能生效 慢sql日志文件在数据库安装路径中的data目录中(前提:打开男sql日志功能) {.is-warning}
- 确定慢sql是哪些后,如何对sql进行优化
- 看慢sql是否使用了*,若是,则改为具体的字段
- 看慢sql是否使用了嵌套查询,此时是否可以将嵌套查询转换为联查,若可以,则使用联查,因为联查的效率高于嵌套
- 检查查询条件部分的字段是否需要使用索引,若需要,确定查询条件字段是否使用了索引,若没有,则添加索引
- 检查查询条件部分的字段是否添加了索引,若添加了索引,检查此时对字段进行查询条件的操作是否导致索引失效
如何优化数据库
- 使用读写分离,主从复制,集群,分库分表
如果主服务宕机了,怎么办?
- 哨兵模式解决这个问题 哨兵系统中存在若干个哨兵实例,每个哨兵实例都会通过心跳机制与所有的服务器保持联系,每个一定的时间哨兵实例回想所有服务器发出ping命令,服务器接收到后会给出响应,若某个哨兵实例没有接收到某台服务器的响应,则主观认为该服务器宕机,但主观认为不代表客观宕机,此时需要确定是否真的宕机。 方式为:该哨兵实例会向其他哨兵发出询问,若超过半数的哨兵都接收不到对应的响应,则客观认为服务器宕机,若宕机的是master,此时哨兵系统会从slave中选举一套作为新的master,将原来的master从集群中移除,并通知其他所有的slave,master发生了改变,让新的master与所有的slave重新建立联系。